Topic: DMD0454

JSONPARSE - Parse JSON TEXT
Note: this instruction can only be used with a BRX CPU !
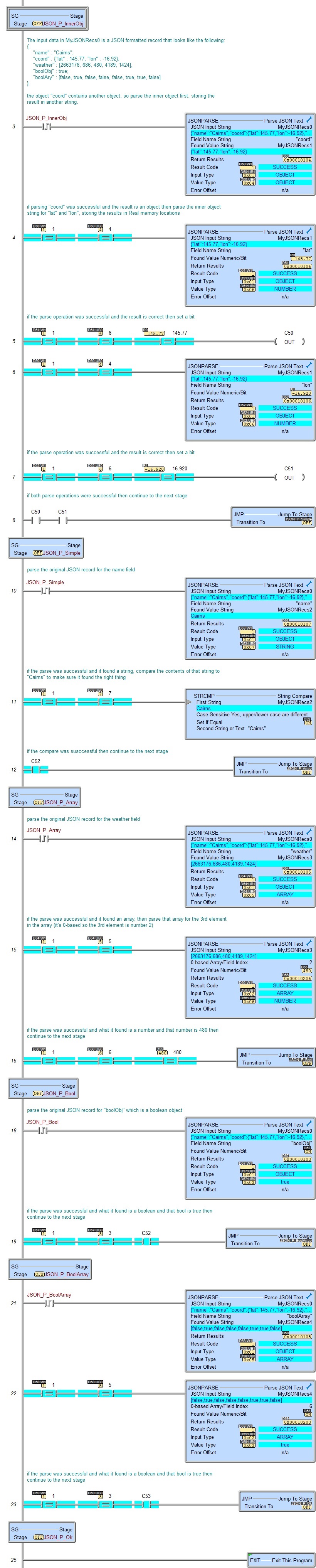
The Parse JSON Text (JSONPARSE) instruction is used to look for a Value in a JSON record associated with either a Field Name, at an Array Index, or at a field index, and place the Value into the specified String, Numeric, or Bit memory location. It is best to know the format of the record before using this instruction. The Field Name is a String. The Value can be text in double quotes, a number, true, false, null, an Array of other values enclosed with square brackets [1,2,3], or a nested Object enclosed with curly brackets {"Nested":42}.
The JSON Input Start Address selects where the JSON record is currently stored in the BRX CPU. Strings are the preferred storage locations for the JSON records because of the ease of working with Strings using other instructions and tools within Do-more Designer. If the JSON record contains 1024 characters or less then always use a String. If the JSON record is more than 1024 characters then first try to reduce the size to less than 1024, for example using a more refined query for the data. If there's no other way to store the JSON record in the PLC as a String then use a Numeric Data Block to contain the text, but when the data is stored this way you will not be able use any of the string manipulation instructions to process the data.
Select String if the JSON record has been stored in a system-defined String, or a user-defined String.
Select Numeric Data Block Containing Text if the JSON record has been stored in a numeric data block (a byte buffer). Note: when using a Numeric Data Buffer to store the text for the JSON Input, use the Memory View with ASCII format to see the contents of the Numeric Data Buffer in readable text form.
Click Create Byte Buffer... to create a new data block of unsigned bytes to store the JSON record. You will need to specify the Data Block Name (1 to 16 letters) names must be unique, and consist of 1 to 16 characters (A-Z, a-z; no numbers, no spaces). The default name is JSONPARSEBuff, but it can be changed. You will also specify Number of Elements is the number of bytes (maximum of 65000) in the data block. The data blocks must be created on a DWord (4-byte) boundary. And specify whether to Make Data Block Retentive (retain values after power loss) will have the data block hold its state through a power cycle or a Program-to-Run mode transition. Memory NOT marked as retentive will be cleared at power up and during a Program-to-Run mode transition.
JSON Input Start Address is the beginning offset into the data block to begin the parse operation.
Number of Bytes is the number of contiguous bytes of the JSON record - beginning at the JSON Input Start Address - to use during the parse operation. Buffer Range will display the range that will be used during the parse operation as it is currently defined.
The Lookup Value by group has selections to determine how search will be performed:
Select Field Name String if the Input Record is an object, the lookup will be done using the text of a Field Name. If the Input Record is an array, this will fail.
Select 0-based Array / Field Index if the lookup is done using an array offset or field index number. If the Input Record is an array, the lookup is done using a 0-based array index. If the Input Record is an object, the lookup is done using a 0-based field index number. When using Field Index option on an object, enable the Found Field Name @Index option below to also get the Field Name of the entry found at the specified Index and store the Field Name in the specified String.
The Found Value group has selections to determine where to place the value that was found:
- Select Text Values that are Strings, Objects, Numbers, Booleans) to store the data that was found as text. Note:use the JSON Pretty Print utility to see the Found Value text formatted for readability.
- Select String (up to 1024 characters) if the Found Value is text the preferred storage location is a String. If the Found Value contains 1024 characters or less then always use a String. If the Found Value is stored in a String you can use any of the string manipulation instructions to process the data. If the Found Value is more than 1024 characters you will need to store it in a Numeric Data Block of Bytes (described below). Click the Create Max Size String... button to create a new String to store the Found Value. Note: if the Found Value is one of the keywords true, false, or "null" and the destination is a String , the contents of the string will be those keywords without the double quotes.
- Select Numeric Data Block Containing Text, or text larger than 1024 characters to store the Found Value in a numeric data block of bytes (a byte buffer), required if the Found Value is larger than 1024 characters. Be aware when the data is stored in a numeric data block you will not be able use any of the string manipulation instructions to further process the data. Note: when using a Numeric Data Buffer to store the text for the Found Value, use the Memory View with ASCII format to see the contents of the Numeric Data Buffer in readable text form.
Click Create Byte Buffer... to create a new data block of unsigned bytes to store the Found Value. You will need to specify the Data Block Name (1 to 16 letters) names must be unique, and consist of 1 to 16 characters (A-Z, a-z; no numbers, no spaces). The default name is JSONPARSEBuff, but it can be changed. You will also specify Number of Elements is the number of bytes (maximum of 65000) in the data block. The data blocks must be created on a DWord (4-byte) boundary. And specify whether to Make Data Block Retentive (retain values after power loss) will have the data block hold its state through a power cycle or a Program-to-Run mode transition. Memory NOT marked as retentive will be cleared at power up and during a Program-to-Run mode transition.
Found Value Text Start Address is the beginning offset into the specified byte buffer to begin storing the Found Value.
Buffer Size in Bytes is the maximum number of characters you want to allow the output record to use in the specified Byte buffer. This can be any constant value from 1 to the maximum size of the Byte buffer. Buffer Range will display the full range of the Numeric Data Block as it is currently defined.
Number of Bytes Parsed is a numeric location that will contain the number of contiguous bytes the Found Value consumed in the specified Byte buffer. This can be any writable numeric location.
- Select Numeric / Bit (for Number, Boolean) if the value is a number and should be placed in a numeric location or a bit location.Note: If the Found Value is true a Boolean destination will be ON or a Numeric memory location will be 1; if the Found Value is false a Boolean destination will be OFF or a Numeric memory location will be 0.
The Return Results value is an encoded 32-bit value. If this option is enabled, the ladder status will break this value into its relevant parts and display them as follows:
Result Code is the upper Word (16-bits). When the Result code is 0 or 1 (well formed), the lower Word is split up into 2 (hexadecimal) unsigned byte values: the Input Type and the Value Type. When the Result Code is negative ( which indicates an error), the lower Word (16-bits) is the offset to character position of the error.
0 means the JSON record is well formed but lookup was not successful, either the Field Name was not found or the Array index was not found.
1 means the JSON record is well formed and the lookup was successful.
Note: error codes (negative result codes) typically mean the JSON record itself was malformed.
-1 means an unexpected character was found at a critical point in the in the JSON record, like a missing comma, brace, or bracket.
-2 means that a Field Name was found with no associated Value.
-3 means that a Value was found with no associated Field Name.
-4 means that the JSON record was so malformed that the parsing operation never got started, again typically a missing comma, brace, or bracket.
Input Type is the upper Byte of the lower Word which indicates what type of data the JSON record contains:
0x00 means the JSON record type is not recognized.
0x01 means the JSON record is a nested Object that contains other JSON components, either Fields, Objects, or Arrays.
0x02 means the JSON record is an Array.
0x03 means the JSON record is a Value.
Value Type is the lower Byte of the lower Word which indicates what type of data the Found Value is:
0x01 means the Value found is a Boolean FALSE.
0x02 means the Value found is NULL.
0x03 means the Value found is a Boolean TRUE.
0x04 means the Value found is an Object, either a Field, another Object.
0x05 means the Value found is an Array
0x06 means the Value found is a Number.
0x07 means the Value found is a text String.
Status Display
See Also
Related Topics
HTTPCMD - HTTP Request / Response with Server
MQTTPUB - IoT Publish MQTT Topics
MQTTSUB - IoT Subscribe to MQTT Topics
Example